Messenger
题意翻译
题目描述 给你两个字符串s,t,求出t在s中出现了多少次。
这两个字符串可能会很长,所以字符串被分成很多块,其中s被分成n块,t被分成m块。每一块(l,c)代表l个c字符连接在一起组成的字符串。即(2,′a′)="aa"。一个字符串ss会被表示成一个序列((l1,c1),(l2,c2),…,(ln,cn))。在输入中字符串"l−c"代表(l,c)。
注意到字符串的表示方式不是唯一的,例如((1,′a′),(3,′a′))=((2,′a′),(2,′a′))="aaaa"。
输入格式 第一行有两个整数n,m;
第二行有n个块,表示字符串s。
第三行有m个块,表示字符串t。
输出格式 一行一个整数:答案。
感谢@ezoixx130 提供的翻译
题目描述
Each employee of the "Blake Techologies" company uses a special messaging app "Blake Messenger". All the stuff likes this app and uses it constantly. However, some important futures are missing. For example, many users want to be able to search through the message history. It was already announced that the new feature will appear in the nearest update, when developers faced some troubles that only you may help them to solve.
All the messages are represented as a strings consisting of only lowercase English letters. In order to reduce the network load strings are represented in the special compressed form. Compression algorithm works as follows: string is represented as a concatenation of $ n $ blocks, each block containing only equal characters. One block may be described as a pair $ (l_{i},c_{i}) $ , where $ l_{i} $ is the length of the $ i $ -th block and $ c_{i} $ is the corresponding letter. Thus, the string $ s $ may be written as the sequence of pairs 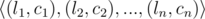.
Your task is to write the program, that given two compressed string $ t $ and $ s $ finds all occurrences of $ s $ in $ t $ . Developers know that there may be many such occurrences, so they only ask you to find the number of them. Note that $ p $ is the starting position of some occurrence of $ s $ in $ t $ if and only if $ t_{p}t_{p+1}...t_{p+|s|-1}=s $ , where $ t_{i} $ is the $ i $ -th character of string $ t $ .
Note that the way to represent the string in compressed form may not be unique. For example string "aaaa" may be given as 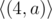, 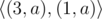, 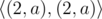...
输入输出格式
输入格式
The first line of the input contains two integers $ n $ and $ m $ ( $ 1<=n,m<=200000 $ ) — the number of blocks in the strings $ t $ and $ s $ , respectively.
The second line contains the descriptions of $ n $ parts of string $ t $ in the format " $ l_{i} $ - $ c_{i} $ " ( $ 1<=l_{i}<=1000000 $ ) — the length of the $ i $ -th part and the corresponding lowercase English letter.
The second line contains the descriptions of $ m $ parts of string $ s $ in the format " $ l_{i} $ - $ c_{i} $ " ( $ 1<=l_{i}<=1000000 $ ) — the length of the $ i $ -th part and the corresponding lowercase English letter.
输出格式
Print a single integer — the number of occurrences of $ s $ in $ t $ .
输入输出样例
输入样例 #1
5 3
3-a 2-b 4-c 3-a 2-c
2-a 2-b 1-c
输出样例 #1
1输入样例 #2
6 1
3-a 6-b 7-a 4-c 8-e 2-a
3-a
输出样例 #2
6输入样例 #3
5 5
1-h 1-e 1-l 1-l 1-o
1-w 1-o 1-r 1-l 1-d
输出样例 #3
0说明
In the first sample, $ t $ = "aaabbccccaaacc", and string $ s $ = "aabbc". The only occurrence of string $ s $ in string $ t $ starts at position $ p=2 $ .
In the second sample, $ t $ = "aaabbbbbbaaaaaaacccceeeeeeeeaa", and $ s $ = "aaa". The occurrences of $ s $ in $ t $ start at positions $ p=1 $ , $ p=10 $ , $ p=11 $ , $ p=12 $ , $ p=13 $ and $ p=14 $ .